
Google | 再见 SharedPreferences 拥抱 Jetpack DataStore(二)
- 如果评论区没有及时回复,欢迎来公众号:ByteCode 咨询
- 公众号:ByteCode。致力于分享最新技术原创文章,涉及 Kotlin、Jetpack、算法、译文、系统源码相关的文章
前言
Google 增加了一个新 Jetpack 的成员 DataStore,主要用来替换 SharedPreferences, 而 Jetpack DataStore 有两种实现方式:
- Proto DataStore:存储类的对象(typed objects ),通过 protocol buffers 将对象序列化存储在本地
- Preferences DataStore:以键值对的形式存储在本地和 SharedPreferences 类似
在上一篇文章 [Google] 再见 SharedPreferences 拥抱 Jetpack DataStore 中介绍了 SharedPreferences 都有那些坑,以及 Preferences DataStore 为我们解决了什么问题。
而今天这篇文章主要来介绍 Proto DataStore,Proto DataStore 通过 protocol buffers 将对象序列化存储在本地,所以首先需要安装 Protobuf 编译 proto 文件,Protobuf 编译大致分为 Gradle 插件编译和命令行编译,这两种方式已经发布到了博客上,欢迎点击下方链接前往查看。
- Protobuf | 安装 Gradle 插件编译 proto 文件
- Protobuf | 如何在 ubuntu 上安装 Protobuf 编译 proto 文件
- Protobuf | 如何在 MAC 上安装 Protobuf 编译 proto 文件
由于目前主要在 MAC 和 ubuntu 上开发,所以只提供了这两种命令行编译方式,如果在 Win 上开发的同学,可以使用 Gradle 插件编译的方式。
这篇文章相关示例,已经上传到 GitHub 欢迎前去仓库 AndroidX-Jetpack-Practice/DataStoreSimple 切换到 datastore_proto 分支查看。
GitHub 地址:https://github.com/hi-dhl/AndroidX-Jetpack-Practice
通过这篇文章你将学习到以下内容:
- 为何要有 Proto DataStore?
- 什么序列化?什么是对象序列化?什么是数据的序列化?
- 什么是 Protocol Buffer?为什么需要它?为我们解决了什么问题?
- 如何在项目中使用 Proto DataStore?
- 如何迁移 SharedPreferences 到 Proto DataStore?
- proto2 和 proto3 语法如何选择?
- 常用 proto3 语法解析?
- MAD Skills 是什么?
为何要有 Proto DataStore
既生 Preference DataStore 何生 Proto DataStore,它们之间有什么区别?
- Preference DataStore 主要是为了解决 SharedPreferences 所带来的性能问题
- Proto DataStore 比 Preference DataStore 更加灵活,支持更多的类型
- Preference DataStore 支持
Int、Long、Boolean、Float、String - protocol buffers 支持的类型,Proto DataStore 都支持
- Preference DataStore 支持
- Preference DataStore 以 XML 的形式存储 key-value 数据,可读性很好
- Proto DataStore 使用了二进制编码压缩,体积更小,速度比 XML 更快
从源码的角度
如果源码部分不是很了解,可以先忽略,继续往下看,之后回过头在来看就能理解了。
Preference DataStore 源码里定义了一个 proto 文件,通过
PreferencesSerializer将每一对key-value数据映射到 proto 文件定义的 message 类型,proto 文件内容如下:syntax = "proto2";
......
message PreferenceMap {
map<string, Value> preferences = 1;
}
message Value {
oneof valueName {
bool boolean = 1;
float float = 2;
int32 integer = 3;
int64 long = 4;
string string = 5;
double double = 7;
}
}在 DataStore 中使用的是 proto2 语法,将 XML 中
key-value数据映射到 Map 中,并且在 proto 文件中只定义了Int、Long、Boolean、Float、String这几种类型。Proto DataStore 我们可以自定义 proto 文件,并实现了
Serializer<T>接口,所以更加灵活,支持更多的类型
刚才说到 Proto DataStore 通过 protocol buffers 使用了二进制编码压缩,将对象序列化存储在本地,那么序列化到底是什么?我们先来了解一些基本概念,方便我们对后续的内容有更好的理解。
序列化
序列化:将一个对象转换成可存储或可传输的状态,数据可能存储在本地或者在蓝牙、网络间进行传输。序列化大概分为对象序列化、数据序列化。
对象的序列化
Java 对象序列化 将一个存储在内存中的对象转化为可传输的字节序列,便于在蓝牙、网络间进行传输或者存储在本地。把字节序列还原为存储在内存中的 Java 对象的过程称为反序列化。
在 Android 中可以通过 Serializable 和 Parcelable 两种方式实现对象序列化。
Serializable
Serializable 是 Java 原生序列化的方式,主要通过 ObjectInputStream 和 ObjectOutputStream 来实现对象序列化和反序列化,但是在整个过程中用到了大量的反射和临时变量,会频繁的触发 GC,序列化的性能会非常差,但是实现方式非常简单,来看一下 ObjectInputStream 和 ObjectOutputStream 源码里有很多反射的地方。
ObjectOutputStream.java |
在 Android 中存在大量跨进程通信,由于 Serializable 性能差的原因,所以 Android 需要更加轻量且高效的对象序列化和反序列化机制,因此 Parcelable 出现了。
Parcelable
Parcelable 的出现解决了 Android 中跨进程通信性能差的问题,而且 Parcelable 比 Serializable 要快很多,因为写入和读取的时候都是采用自定义序列化存储的方式,通过 writeToParcel() 方法和 describeContents() 方法来实现,不需要使用反射来推断它,因此性能得到提升,但是使用起来比 Serializable 要复杂很多。
为了解决复杂性问题, AndroidStudio 也有对应插件简化使用过程,如果是 Java 语言可以使用 android parcelable code generator 插件, 如果 Kotlin 语言的话可以使用 @Parcelize 注解,快速的实现 Parcelable 序列化。
用一张表格汇总一下 Serializable 和 Parcelable 的区别
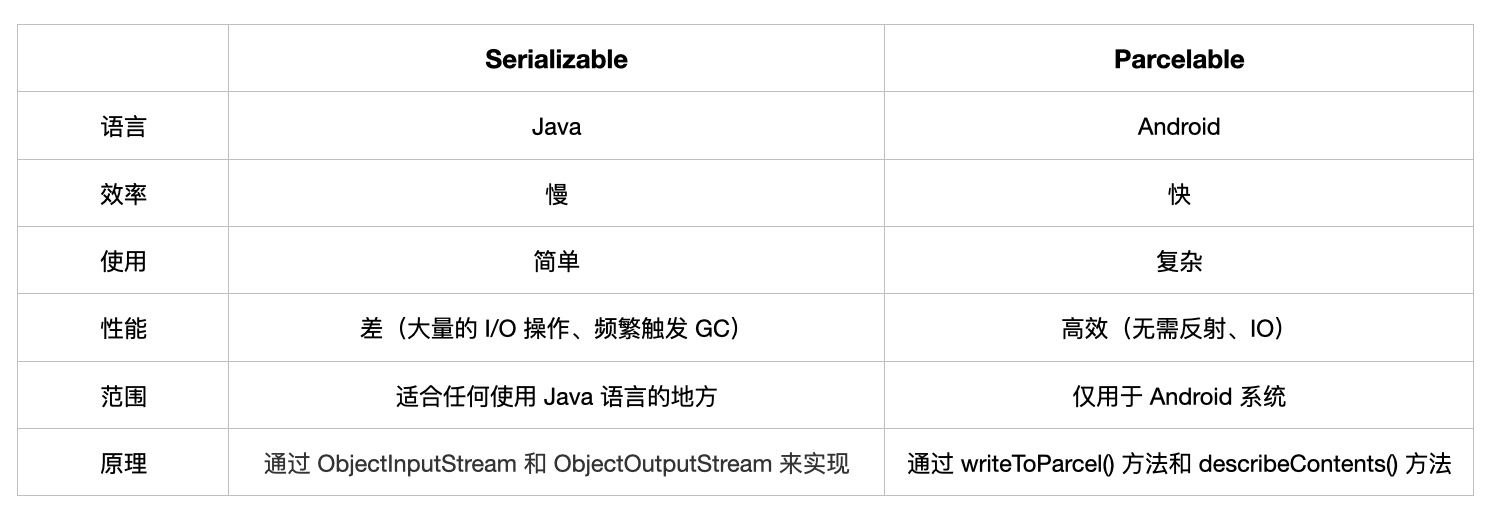
数据序列化
对象序列化记录了很多信息,包括 Class 信息、继承关系信息、变量信息等等,但是数据序列化相比于对象序列化就没有这么多沉余信息,数据序列化常用的方式有 JSON、Protocol Buffers、FlatBuffers。
JSON :是一种轻量级的数据交互格式,支持跨平台、跨语言,被广泛用在网络间传输,JSON 的可读性很强,但是序列化和反序列化性能却是最差的,解析过程中,要产生大量的临时变量,会频繁的触发 GC,为了保证可读性,并没有进行二进制压缩,当数据量很大的时候,性能上会差一点。
Protocol Buffers :它是 Google 开源的跨语言编码协议,可以应用到
C++、C#、Dart、Go、Java、Python等等语言,Google 内部几乎所有 RPC 都在使用这个协议,使用了二进制编码压缩,体积更小,速度比 JSON 更快,但是缺点是牺牲了可读性RPC 指的是跨进程远程调用,即一个进程调用另外一个进程的方法。
FlatBuffers :同 Protocol Buffers 一样是 Google 开源的跨平台数据序列化库,可以应用到
C++、C#,Go、Java、JavaScript、PHP、Python等等语言,空间和时间复杂度上比其他的方式都要好,在使用过程中,不需要额外的内存,几乎接近原始数据在内存中的大小,但是缺点是牺牲了可读性
最后我们用一张图来分析一下 JSON、Protocol Buffers、FlatBuffers 它们序列化和反序列的性能,数据来源于 JSON vs Protocol Buffers vs FlatBuffers
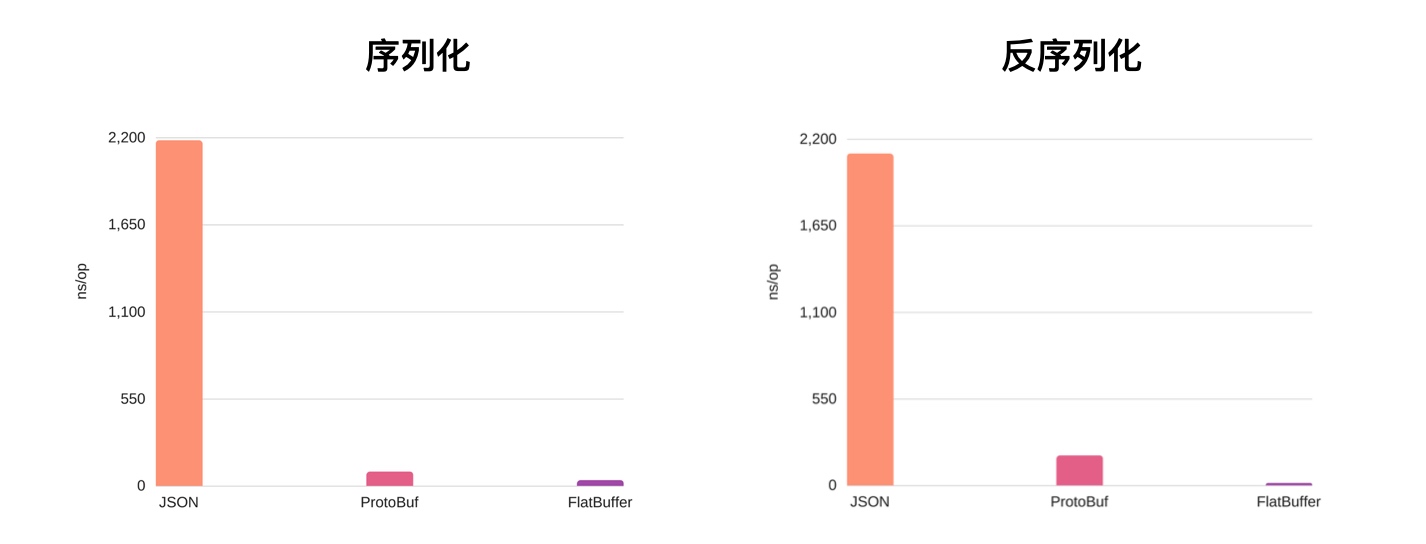
FlatBuffers 和 Protocol Buffers 无论是序列化还是反序列都完胜 JSON,FlatBuffers 最初是 Google 为游戏或者其他对性能要求很高的应用开发的,接下来我们来看一下今天主角 Protocol Buffer。
Protocol Buffer
Protocol Buffer ( 简称 Protobuf ) 它是 Google 开源的跨语言编码协议,可以应用到 C++ 、C# 、Dart 、Go 、Java 、Python 等等语言,Google 内部几乎所有 RPC 都在使用这个协议,使用了二进制编码压缩,体积更小,速度比 JSON 更快。
从 Proto3.0.0 Release Note 得知: protocol buffers 最初开源时,它实现了 Protocol Buffers 语言版本 2(称为 proto2), 这也是为什么版本数从
v2.0.0开始,从v3.0.0开始, 引入新的语言版本(proto3),而旧的版本(proto2)继续被支持。所以到目前为止 Protobuf 共两个版本 proto2 和 proto3。
proto2 和 proto3 应该学习那个版本?
proto3 简化了 proto2 的语法,提高了开发的效率,因此也带来了版本不兼容的问题,因为 2019 年的时候才发布 proto3 稳定版本,所以在这之前使用 Protocol Buffer 的公司,大部分项目都是使用 proto2 的版本,从上文的源码分析部分可知,在 DataStore 中使用了 proto2 语法,所以 proto2 和 proto3 这两种语法都同时在使用。
对于初学者而言直接学习 proto3 语法就可以了,为了适应技术迭代的变化,当掌握 proto3 语法之后,可以顺带了解一下 proto2 语法以及 proto3 和 proto2 语法的区别,这样可以更好的理解其他的开源项目。
为了避免混淆 proto3 和 proto2 语法,在本文仅仅分析 proto3 语法,当我们了解完这些基本概念之后,我们开始分析 如何在项目中使用 Proto DataStore。
如何在项目中使用 Proto DataStore
Proto DataStore 同 Preferences DataStore 一样主要应用在 MVVM 当中的 Repository 层,在项目中使用 Proto DataStore 非常简单。
1. 添加 Proto DataStore 依赖
在 app 模块 build.gradle 文件内,添加以下依赖
// Proto DataStore |
Google 推荐 Android 开发使用 protobuf-javalite 因为它的代码更小,做了大量的优化。
当添加完依赖之后需要新建 proto 文件,在本文示例项目中新建了一个 common-protobuf 模块,将新建的 person.proto 文件,放到了 common-protobuf 模块 src/main/proto 目录下。
proto 文件默认存放路径
src/main/proto,也可以通过修改 gradle 的配置,来修改默认存放路径
在 common-protobuf 模块,build.gradle 文件内,添加以下依赖
implementation "com.google.protobuf:protobuf-javalite:3.10.0" |
2. 新建 Person.proto 文件,添加以下内容
syntax = "proto3"; |
syntax:指定 protobuf 的版本,如果没有指定默认使用 proto2,必须是.proto文件的除空行和注释内容之外的第一行option:表示一个可选字段java_package: 指定生成 java 类所在的包名java_outer_classname: 指定生成 java 类的名字
message中包含了一个 string 类型的字段(name)。注意 :=号后面都跟着一个字段编号- 每个字段由三部分组成:字段类型 + 字段名称 + 字段编号,在 Java 中每个字段会被编译成 Java 对象
在这里只需要了解这些 proto 语法即可,在文章后面会更详细的介绍这些语法。
3. 执行 protoc ,编译 proto 文件
以输出 Java 文件为例,执行以下命令即可输出对应的 Java 文件,如果配置了 Gradle 插件,可以忽略这一步,直接点击 Build -> Rebuild Project 即可生成对应的 Java 文件。
protoc --java_out=./src/main/java -I=./src/main/proto ./src/main/proto/*.proto |
--java_out: 指定输出 Java 文件所在的目录-I:指定 proto 文件所在的目录*.proto: 表示在-I指定的目录下查找以.proto结尾的文件
4. 构建 DataStore
object PersonSerializer : Serializer<PersonProtos.Person> { |
- 实现了
Serializer<T>接口,这是为了告诉 DataStore 如何从 proto 文件中读写数据 PersonProtos.Person是通过编译 proto 文件生成的 Java 类Person.parseFrom(input)是编译器自动生成的,用于读取并解析 input 的消息t.writeTo(output)是编译器自动生成的,用于写入序列化消息
5. 从 Proto DataStore 中读取数据
fun readData(): Flow<PersonProtos.Person> { |
- DataStore 是基于 Flow 实现的,所以通过
dataStore.data会返回一个Flow<T>,每当数据变化的时候都会重新发出 catch用来捕获异常,当读取数据出现异常时会抛出一个异常,如果是IOException异常,会发送一个PersonProtos.Person.getDefaultInstance()来重新使用,如果是其他异常,最好将它抛出去
4. 向 Proto DataStore 中写入数据
在 Proto DataStore 中是通过 DataStore.updateData() 方法写入数据的,DataStore.updateData() 是一个 suspend 函数,所以只能在协程体内使用,每当遇到 suspend 函数以挂起的方式运行,并不会阻塞主线程。
以挂起的方式运行,不会阻塞主线程 :也就是协程作用域被挂起, 当前线程中协程作用域之外的代码不会阻塞。
首先我们需要创建一个 suspend 函数,然后调用 DataStore.updateData() 方法写入数据即可。
suspend fun saveData(personModel: PersonModel) { |
person.toBuilder() 是编译器为每个类生成 Builder 类,用于创建消息实例
到这里关于 Proto DataStore 读取数据和写入数据已经全部分析完了,接下来分析一下如何迁移 SharedPreferences 到 Proto DataStore。
迁移 SharedPreferences 到 Proto DataStore
迁移 SharedPreferences 到 Proto DataStore 只需要 3 步
1. 创建映射关系
将 SharedPreferences 数据迁移到 Proto DataStore 中,需要实现一个映射关系,将 SharedPreferences 中每一对 key-value 数据映射到 proto 文件定义的 message 类型。
private val shardPrefsMigration = |
- 获取 SharedPreferences 存储的
key = ByteCode的值 - 将
key = ByteCode数据映射到 Person 的成员变量 followAccount 中
2. 构建 DataStore 并传入 shardPrefsMigration
protoDataStore = context.createDataStore( |
- 当 DataStore 对象构建完了之后,需要执行一次读取或者写入操作,即可完成 SharedPreferences 迁移到 DataStore,当迁移成功之后,会自动删除 SharedPreferences 使用的文件,Proto DataStore 和 Preferences DataStore 文件存储路径都是一样的,如下图所示

到这里关于 Jetpack DataStore 实现方式之一 Proto DataStore 全部都分析完了,我们一起来看一下 proto 语法。
常用的 proto3 语法
我梳理了常用的 proto3 语法,应该能满足大部分情况,更多语法可以参考 Google 官方教程 ,当掌握 proto3 语法之后,可以顺带了解一下 Proto2 语法,Proto3 虽然简化了 Proto2 的使用,提高了开发的效率,但是因为版本兼容问题,对于早期使用 Protocol Buffer 的团队,大部分都是使用 Proto2 语法。
一个基本的消息类型
syntax = "proto3"; |
syntax:指定 protobuf 的版本,如果没有指定默认使用 proto2,必须是.proto文件的除空行和注释内容之外的第一行option:表示一个可选字段java_package: 指定生成 java 类所在的包名java_outer_classname: 指定生成 java 类的名字
- 在一个 proto 文件中,可以定义多个 message
message中包含了 3 个字段:一个 string 类型(name)、一个整型类型(age)、一个 bool 类型(followAccount)。注意 :=号后面都跟着一个字段编号- 每个字段由三部分组成:字段类型 + 字段名称 + 字段编号,在 Java 中每个字段会被编译成 Java 对象,其他语言会被编译其他语言类型
字段类型
每一个消息类型中包含了很多个消息字段,每个消息字段都有一个类型,接下里用一个表格展示 proto 文件中的类型,以及对应的 Java 类型,如果其他语言可以查看官方文档。
| .proto Type | Notes | Java Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码,如果字段是负值,效率很低,使用 sint32 代替 | int |
| int64 | 使用变长编码。如果字段是负值,效率很低,使用 sint64 代替 | long |
| sint32 | 使用变长编码,如果是负值比普通的 int32 更高效 | int |
| sint64 | 使用变长编码,如果是负值比普通的 int64 更高效 | long |
| bool | boolean | |
| string | 字符串必须始终包含 UTF-8 编码或 7-bit ASCII 文本,长度不能超过23 | String |
以上类型是经常会用到的,当然还有其他类型:uint32 、 uint64 、 fixed32 、 fixed64 、 sfixed32 、 sfixed64 、 bytes 等等,更多编码类型可以点击这里查看 Encoding
字段默认值
在 Proto3 中使用以下规则,编译成 Java 语言的默认值:
- 对于 string 类型,默认值为空字符串(
"") - 对于 byte 类型,默认值是一个大小为 0 空 byte 数组
- 对于 bool 类型,默认为 false
- 对于数值类型,默认值为 0
- 对于枚举类型,默认值是第一个定义的枚举值, 且这个值必须是 0 (这是为了兼容 proto2 语法)
- 使用其他消息类型用作字段类型,默认值是 null (下文会详细分析)
- 被 repeated 修饰字段,默认值是一个大小为 0 的空 List
字段编号
在每一个消息字段 = 号后面都跟着一个字段编号,如下所示:
string name = 1; |
字段编号用于在消息的二进制格式中识别各个字段,字段编号非常重要,一旦开始使用就不能够再改变,字段编号的范围在 [1, 2^29 - 1] 之间,其中 [19000-19999] 作为 Protobuf 预留字段,不能使用。
注意 :在范围 [1, 15] 之间的字段编号在编码的时候会占用一个字节,包括字段编号和字段类型,在范围 [16, 2047] 之间的字段编号占用两个字节,因此,应该为频繁出现的消息字段保留 [1, 15] 之间的字段编号,一定要为将来频繁出现的元素留出一些空间。
repeated
在刚才的示例中,我给一个字段添加了 repeated 修饰符,如下所示:
repeated string phone = 4; |
被 repeated 修饰的字段,对应 Java 类型中的 List,来看一下编译后的代码。
private com.google.protobuf.Internal.ProtobufList<java.lang.String> phone_; |
ProtobufList 其实是 List 子类,如下所示:
public static interface ProtobufList<E> extends List<E> |
包含其他消息类型
消息字段除了可以使用 int32 、 bool 、string 等等作为字段类型,还可以使用其他消息类型作为字段类型,如下所示:
message Person { |
消息嵌套
在一个 proto 文件中,可以定义多个 message 如下所示:
message Person { |
当然 message 也是可以层级嵌套的,来看个示例:
message Person { |
这些 message 会被编译成静态内部类,如下所示:
public static final class Address extends |
枚举类型
同样我们可以给 message 添加枚举类型,也可以使用枚举类型作为字段类型,如下所示:
message Person { |
正如你所看到的,消息字段除了可以使用 int32 、 bool 、string 、其他消息类型作为字段类型之外,还可以使用枚举类型作为字段类型。
注意 :每一个枚举类型第一个枚举值必须为 0,因为:
- 必须有一个 0 值,因为需要将 0 作为默认值
- 值为 0 的元素必须是第一个枚举值,这是为了兼容 proto2 语法,在 proto2 中默认值总是第一个枚举值
oneof
根据 Google 文档分析 oneof 有两层意思:
- 在 oneof 中声明多个字段,同时只有一个字段会被赋值,共享一块内存,主要用来节省内存
- 如果 oneof 当中一个字段被赋值,然后在给其他字段赋值,会清除其他已赋值字段的值,最终 oneof 所有字段中只会有一个字段有值
我们来看一下简单的示例
message PreferenceMap { |
- 在一个名为 valueName 的 oneof 中声明了很多个字段,这些字段会共享一块内存空间,同时只有一个字段会被赋值
- 在名为 PreferenceMap 的 message 中声明了一个 map,Key 是字符串类型,Value 其实是 oneof 中声明的字段,同一时间,一个 Key 只会对应一个 Value
其实在编译的时候,会为每个 oneof 生成一个 Java 枚举类型,代码如下所示
public enum ValueNameCase { |
编译器会自动生成 getValueNameCase() 方法,用来检查哪个字段被赋值了,如果都没有赋值,会返回 VALUENAME_NOT_SET
常用的 proto3 语法到这里就介绍完了,文章只列举了常用的语法,如果需要把 proto3 语法都分析完,至少需要 2 篇文章才有可能介绍完,因为篇幅原因,源码分析部分会在后续的文章中分析。
MAD Skills 是什么
Google 近期发布了 MAD Skills(Modern Android Development)新系列教程,旨在帮助开发者使用最新的技术,开发更好的应用程序,以视频和文章形式介绍 MAD 各个部分,包括 Kotlin、Android Studio、Jetpack、App Bundles 等等, Google 仅仅提供了视频和文章,我在这基础上,我做了一些扩展:
- 视频添加上了中英文字幕,帮助更好的学习
- 视频的实战部分,将会提供对应的实战案例
- 除了实战案例,还会提供对应的源码分析
每隔几个星期 Google 会发布一系列教程,目前已经开始了一系列关于导航组件 (Navigation component) 的视频教程。双语视频已经同步到 GitHub 仓库 MAD-Skills 可以先看视频部分,文章以及案例正在火速赶来。
参考文章
- Google-DataStore – Jetpack Alternative For SharedPreferences
- Google-Language Guide (proto3)
- GitHub-protobuf
- FlatBuffers 体验
- Java 对象序列化
- JSON vs Protocol Buffers vs FlatBuffers
总结
全文到这里就结束了,文章中相关的示例,已经上传到 GitHub 欢迎前去仓库 AndroidX-Jetpack-Practice/DataStoreSimple 切换到 datastore_proto 分支查看。
GitHub 地址:https://github.com/hi-dhl/AndroidX-Jetpack-Practice
当这篇文章写完时,已经写了 4 篇文章了,在准备写这篇文章之前,写了三篇文章介绍了 MAC 和 ubuntu 两种命令行编译方式以及 Gradle 插件的方式编译 proto 文件,因为看了下网上的方式都太老了,而且也不是很清楚,Gradle 插件的方式网上大部分都是 3.0.x ~ 3.7.x 的配置方式,当 protoc >= 3.8 之后有一些不同之处,所以重新写了这三种编译方式,以及记录了在这个过程中遇到的问题。
- Protobuf | 安装 Gradle 插件编译 proto 文件
- Protobuf | 如何在 ubuntu 上安装 Protobuf 编译 proto 文件
- Protobuf | 如何在 MAC 上安装 Protobuf 编译 proto 文件
由于目前主要在 MAC 和 ubuntu 上开发,所以只提供了这两种命令行编译方式,如果在 Win 上开发的同学,可以使用 Gradle 插件编译的方式,如果有帮助 点个赞 就是对我最大的鼓励!
- 本文作者:hi-dhl
- 本文标题:Google | 再见 SharedPreferences 拥抱 Jetpack DataStore(二)
- 本文链接:https://hi-dhl.com/2020/11/08/jetpack/12-porot-datastore/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 hi-dhl
